Les bases de donnees : SQL
![]()
![]()
![]()
![]()
![]()
![]()
Les bases de donnees : SQL
|
|
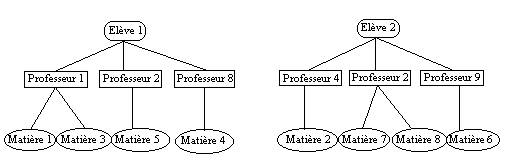
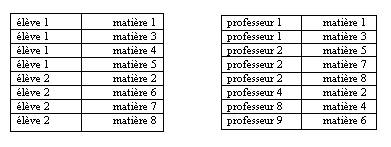
1.1 : Introduction et Généralités 1.1.1 : Ensemble de données structuré L'informatique est une science du traitement de l'information; laquelle est représentée par des données qui permettent d'en avoir un codage permettant son traitement. Aussi, très tôt, on s'est intéressé aux diverses manières de pouvoir stocker des données. Les données sont stockées dans des périphériques dont les supports physiques ont évolué dans le temps: en autres, d'abord des bandes magnétiques, des mémoires à bulles, puis aujourd'hui des disques magnétiques, ou des CD-ROM. La notion de fichier est très rapidement apparue: le fichier regroupe tout d'abord des objets de même nature. Pour rendre facilement exploitables les données d'un fichier, on a pensé à différentes méthodes d'accès (accès séquentiel, direct, indexé). Toute application qui gère des systèmes physiques doit disposer de paramètres décrivant ces systèmes afin de pouvoir en faire des traitements. Dans des systèmes de gestion de clients les paramètres sont très nombreux (noms, prénoms, adresse, n°Sécu, Sport favori, Est satisfait ou pas,..) et divers (alphabétiques, numériques, booléens, ...). Très vite il a fallu trouver un moyen de stocker ces données d'une manière qui soit facilement accessible. Pas question de tout enregistrer en vrac dans un fichier: il faut plusieurs fichiers afin de regrouper les informations par catégorie, et pas question de faire cela sans avoir au préalable pensé à une structure. Voilà ce qu'est une base de données: un ensemble structuré de données.
Plusieurs données peuvent se retrouver stockées dans plusieurs fichiers à la
fois: il était plus rentable en terme de place occupée et aussi de temps de
penser à une structure qui permette d'éviter ceci. Une base de données
remplace un ensemble de fichiers et permet de fournir une structuration des données. 1.1.2 : Ensemble de données universel Une base de données doit être structurée, mais sa structuration doit avoir un caractère universel: il ne faut pas que cette structure soit adaptée à une application particulière, mais qu'elle puisse être utilisable par plusieurs applications distinctes. En effet, un même ensemble de données peut être commun à plusieurs systèmes de traitement dans un problème physique (par exemple la liste des élèves d'un établissement peut servir au service de restauration à compter combien de plats ils doivent préparer et au service de gestion des élèves à pouvoir éditer des bulletins à chaque nom).
Le caractère universel de cette structuration entend une vision abstraite de
l'objet "Base de données". Les programmes étant indépendants des
données, ces dernières peuvent donc être manipulées et changées indépendamment
du programme qui y accédera en implantant les méthodes générales d'accès
aux données de la base conformément à sa structuration abstraite. 1.1.3 : Les modèles de données Il
existe deux niveaux de modèles pour une base de données:
Il
existe 3 grands modèles logiques pour décrire les bases de données:
Le choix d'un modèle plutôt qu'un autre va dépendre d'une certaine particularité des données que l'on cherche à représenter, mais l'expérience a montré que le modèle relationnel était le plus simple en terme d'indépendance des données par rapport aux applications et de facilité de représenter les données dans notre esprit. Le modèle relationnel se base sur les relations que les objets ont les uns avec les autres, et il est décrit par un modèle mathématique relationnel qui permet d'assurer des fondements certains à sa structuration. Les
inconvénients de dépendance aux données mentionnés ci-haut concernant les
deux autres modèles, ont probablement conduit à répandre le plus largement le
modèle relationnel; c'est donc celui que nous utiliserons. 1.1.4 : SGBD et langage SQL En plus de pouvoir être accessibles par plusieurs applications distinctes, certaines bases de données doivent être accessibles par plusieurs applications simultanément (plusieurs personnes travaillant avec des applications différentes sur différents postes accédant par réseau à une base de donnée commune ne se consultent pas pour accéder chacune leur tour à la base de données avec leur application) : il faut alors gérer l'accès aux données de manière à éviter des erreurs. Ainsi les bases de données doivent être "chapeautées" par un système de gestion qui permet de contrôler les accès à la base de données elle-même et qui fait interface entre le modèle logique de la base de données (l'organisation logique des données) et son modèle physique (l'organisation des données sur le support): c'est le S.G.B.D. (Système de Gestion de Bases de Données) qui s'occupe de tout cela. Un SGBD permet donc de gérer une base de données. A ce titre il offre de nombreuses fonctionnalités supplémentaires à la gestion d'accès simultanés à la base et à un simple interfaçage entre le modèle logique et le modèle physique: il sécurise les données (en cas de coupure de courant ou autre défaillance matérielle), il permet d'accéder aux données de manière confidentielle (en assurant que seuls certains utilisateurs ayant des mots de passe appropriés peuvent accéder à certaines données),il ne permet de mémoriser des données que si elles sont du type abstrait demandé: on dit qu'il vérifie leur intégrité (des données alphabétiques ne doivent pas être enregistrées dans des emplacement pour des données numériques,...)...
Mais pour pouvoir accéder aux données, une application doit pouvoir
"parler" au SGBD: elle le fait par le moyen d'un langage de
manipulation des données. Il existe de nombreux langages de manipulation des
données. Le langage SQL est un de ces langages, qui s'est largement démocratisé
et est aujourd'hui le langage principalement adopté. 1.2 : Contenu
d'une base de données relationnelle 1.2.1 : Les tables Essentiellement, une base de données contient un ensemble de tables. Qu'est-ce qu'une table?
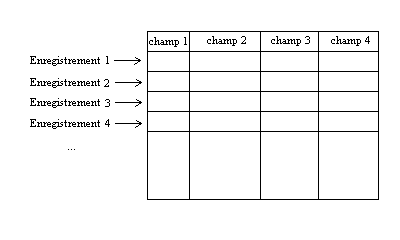
C'est une structure possédant une
liste de Champs (ou rubriques). Les champs sont comme des en-têtes d'un tableau à 2 dimensions, indiquant le type de contenu de la colonne du tableau (par exemple un champ contiendra des données alphabétiques pour stocker des noms, un autre champ contiendra des données numériques pour stocker des âges,...). Chaque champ contiendra une seule valeur. Chaque ligne de ce tableau est appelée un "enregistrement". Un enregistrement est donc une suite de données , chacune appartenant à un champ donné (donc chaque donnée de la liste de l'enregistrement est du type du champ auquel elle appartient).
L'objet table est en fait constitué de deux éléments différents: d'une part
la structure elle-même, c'est à dire la liste des champs, l'ordre dans lequel
ils apparaissent, ainsi que les propriétés de ces champs (nombre de caractères
dans le cas d'un champ alphabétique, plus grand nombre représentable dans le
cas d'un champ numérique,...); puis d'autre part les données contenues dans la
table. Une table vide de données existe toujours de par sa structure. Créer
une table, c'est créer une structure, y ajouter des données, c'est remplir
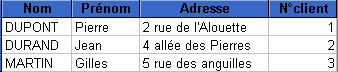
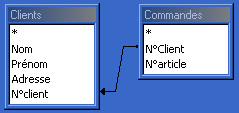
cette table. 1.2.2 : Les requêtes Par exemple on peut disposer d'une table définissant des clients (noms, prénoms, adresses, n° de client) et d'un autre table associant des numéros de clients avec des numéros de commande d'articles, et vouloir poser la question: quels sont les noms des clients ayant passé des commandes?. Pour formuler une requête, il faut s'adresser au SGBD grâce à un langage de manipulation des données: le langage SQL. Une requête est donc une instruction de type langage de programmation, respectant la norme SQL, permettant de réaliser un tel questionnement. L'exécution d'une requête permet d'extraire des données en provenance de tables de la base de données: ces données réalisent ce que l'on appelle une projection de champs (en provenance de plusieurs tables). Le résultat d'exécution d'une requête est une table constituée par l'ensemble des champs projetés. Exemple de projection de champs à
partir des deux tables suivantes correspondant à l'exemple énoncé précédemment:
Formulation
d'une projection des champs Nom (table Clients) et N°article (table Commandes)
suivant la question: extraire les Noms et les N°article des clients dont les N°Client
de la table "Clients" se retrouvent dans la table
"Commandes". SELECT
Clients.Nom, Commandes.[N°article] La table créée comme résultat de cette requête (et contenant les champs projetés "Nom" et "N°article") est la suivante:
La table créée par l'exécution de la requête n'est pas stockée dans la base de données: c'est une table temporaire qui est uniquement résultat d'exécution du SQL. On peut ajouter à la requête SQL des instructions demandant de stocker cette table dans la Base de données, ou de faire des mises à jour de contenus d'autres tables de la base avec les données obtenues par cette table-ci. Une requête peut être stockée dans la base de données sous la forme d'un fichier contenant le texte SQL de la requête. C'est l'un des autres objets qui peuvent faire partie d'une base de données. On
voit l'importance d'apprendre le langage SQL pour pouvoir manipuler les données
de la base. 1.2.3 : Les relations entre objets
Une base de données relationnelle est basée sur une description de relations. Des champs de tables différentes de la base peuvent être mis en relation suivant certaines contraintes (dans l'exemple du 2.2 on a mis en relation le champ "N°Client" de la table "Clients" et le champ "N°Client" de la table "Commandes").
Ces relations sont définies à la création des tables, et le SGBD stocke généralement
ces relations dans des tables cachées et protégées contre des manipulations
de l'utilisateur, qui sont enregistrées dans la base de données. En effet, le
SGBD doit être le seul intermédiaire pour structurer la base de données afin
de pouvoir vérifier que les opérations et les contraintes demandées par
l'utilisateur sont possibles et autorisées. |
|
|